
Forge turns PyTorch models into optimized CUDA and Triton kernels automatically. 32 AI agents run in parallel, each trying different optimization strategies like tensor cores, memory coalescing, and kernel fusion. A judge validates every kernel for correctness before benchmarking. We got 5x faster inference than torch.compile on Llama 3.1 8B and 4x on Qwen 2.5 7B. Works on any PyTorch model. Free trial on one kernel. Full credit refund if we don't beat torch.compile.
Lumecoder
Official-parity experience, lower price, higher value, 5-10x better value.

The AI that actually does things

All-in-one growth OS for serious 𝕏 creators
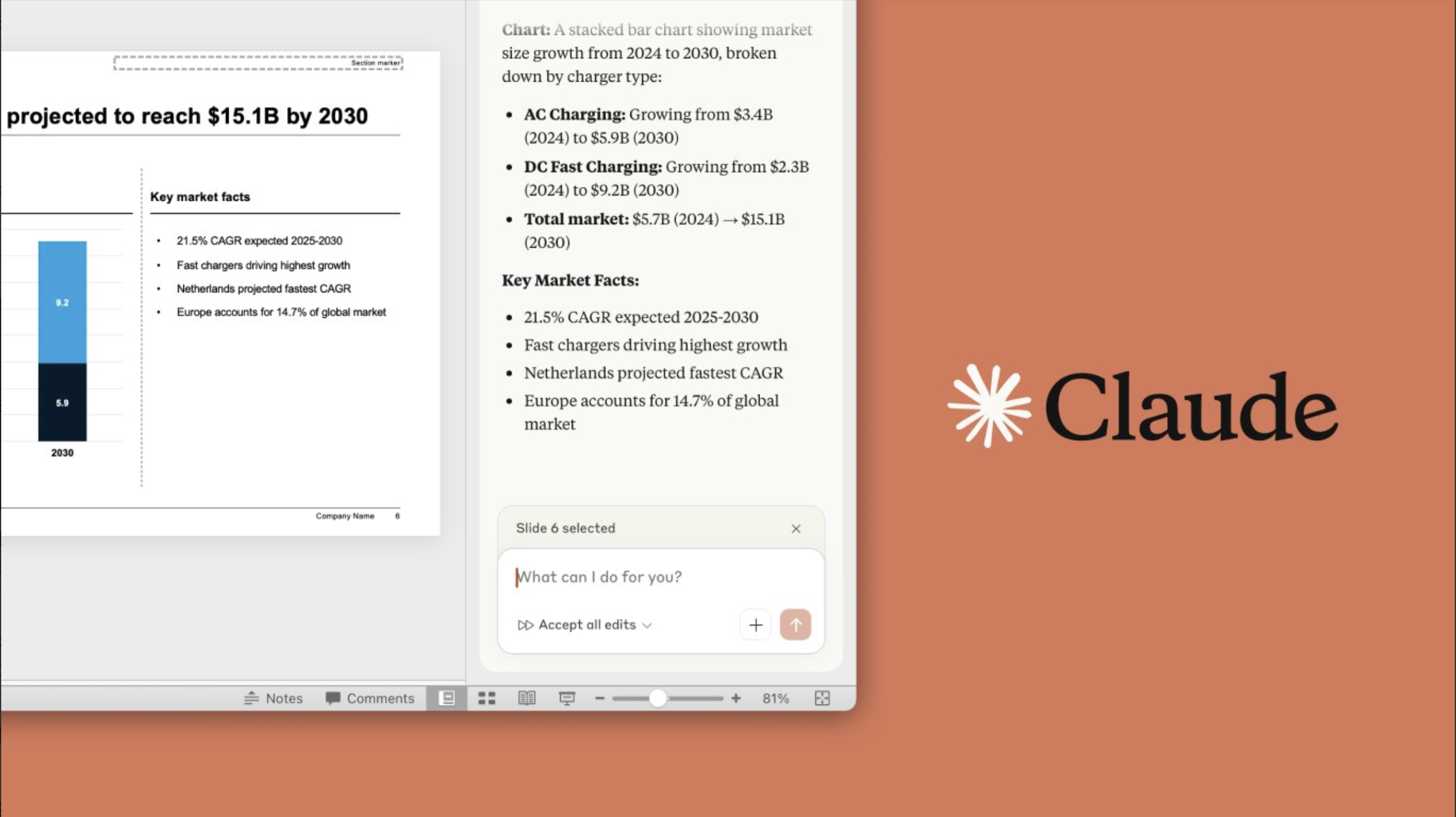
Use Claude to build, edit & refine PowerPoint presentations.
The most capable Sonnet model yet
The agent-native computer, for the rest of us
Build real apps, not prototypes
